- Research
- Open access
- Published:
Document-level medical relation extraction via edge-oriented graph neural network based on document structure and external knowledge
BMC Medical Informatics and Decision Making volume 21, Article number: 368 (2021)
Abstract
Objective
Relation extraction (RE) is a fundamental task of natural language processing, which always draws plenty of attention from researchers, especially RE at the document-level. We aim to explore an effective novel method for document-level medical relation extraction.
Methods
We propose a novel edge-oriented graph neural network based on document structure and external knowledge for document-level medical RE, called SKEoG. This network has the ability to take full advantage of document structure and external knowledge.
Results
We evaluate SKEoG on two public datasets, that is, Chemical-Disease Relation (CDR) dataset and Chemical Reactions dataset (CHR) dataset, by comparing it with other state-of-the-art methods. SKEoG achieves the highest F1-score of 70.7 on the CDR dataset and F1-score of 91.4 on the CHR dataset.
Conclusion
The proposed SKEoG method achieves new state-of-the-art performance. Both document structure and external knowledge can bring performance improvement in the EoG framework. Selecting proper methods for knowledge node representation is also very important.
Background
Relation extraction (RE) that extracts relations among entities in the text is a fundamental task of natural language processing (NLP). There may be two kinds of RE: (1) sentence-level RE that extracts relations in the same sentence, called intra-sentence relations; (2) document-level RE that extracts relations in the same sentence and cross sentences, and the relations cross sentences are called inter-sentence relations. Compared with sentence-level RE, document-level RE is more challenging as document-level RE needs to consider both intra-sentence relations and inter-sentence relations as a whole, as shown in Fig. 1.

Example of document-level relation extraction
In recent years, document-level RE has attracted more and more attention from researchers, and various kinds of machine learning methods have been proposed. Among these methods, multi-instance learning (MIL) first introduced by Riedel et al. [1] for document-level RE is one of the most popular. MIL models multiple entity mention pairs of the same two given entities over a document and has the ability to reduce noise in distant supervised learning [2, 3]. Although the existing MIL methods achieve considerable results, they also have some disadvantages. One disadvantage of these methods is that all entity pairs are considered individually and the implicit correlations among entities in different pairs in a document are ignored.
Graph neural networks (GNNs) that can represent the whole document and consider implicit correlations among entities in different pairs have shown great potential for document-level RE [4,5,6,7,8,9,10]. They may fall into two categories: (1) node-oriented GNNs [4,5,6,7,8,9]; (2) edge-oriented GNNs (denoted by EoG) [10]. Node-oriented GNNs mainly focus on node representation, while edge-oriented GNNs mainly focus on edge representation. As a relation between two entities is an instinctive edge in GNNs, edge-oriented GNNs outperformed node-oriented GNNs on document-level RE in some studies [10, 11]. In the case of EoG, document structure and external knowledge have been proved meaningful. However, there is no study to investigate them comprehensively.
In this study, based on the backbone of EoG, we propose a novel GNN to consider document structure and external knowledge for document-level RE comprehensively, called SKEoG, which is an extension of KEoG proposed in our previous study [11]. To evaluate SKEoG, we conduct experiments on two public medical datasets. Experiment results show that both document structure and external knowledge are beneficial to documental-level medical RE in the backbone of EoG, and the proposed SKEoG model achieves new state-of-the-art performance, outperforming KEoG.
Related work
The studies most related to our work are EoG [10] and KEoG [11]. EoG is the first edge-oriented GNN for document-level RE proposed by Christopoulou et al. [10]. In EoG, information at different levels, including mention, entity and sentence, are regarded as nodes connected by five types of edges. EoG models document-level relations between entities directly and achieves much better results than node-oriented GNNs [10]. KEoG is an extension of EoG by introducing two new types of nodes regarding the document itself and knowledge concept and two new types of edges to connect the two new types of nodes. KEoG shows much better performance than EoG [11].
Inspired by KEoG [11], we propose a novel EoG that considers document structure and external knowledge comprehensively, that is SKEoG. Based on KEoG, SKEoG further introduces two new types of nodes, one regarding document structure and the other regarding external knowledge such as entity description. In this study, we use three models, that is, TransE [12], RESCAL [13] and GAT [14] to represent knowledge node based on knowledge graph respectively, and use two models, that is Doc2vec [15] and an end-to-end neural network, to represent knowledge node based on entity description.
Methods
In this section, we first introduce RE based on document structure, and then RE based on external knowledge from two aspects: knowledge graph and entity description.
Relation extraction based on document structure
A document usually has a hierarchical structure like an example, as shown in Fig. 2, where a document \(d_{1}\) consists of two chapters \(c_{1}\) and \(c_{2}\), and each chapter contains some sentences with many entity mentions. Suppose that a sentence \(s = w_{1} w_{2} \ldots w_{\left| s \right|}\), it can be represented as \(H_{s}^{local} = \left[ {h_{1}^{local} ,h_{2}^{local} , \ldots ,h_{\left| s \right|}^{local} } \right]\) via an encoding layer.

Example of document structure
In a document with |d| sentences \(d = s_{1} ,s_{2} , \ldots ,s_{\left| d \right|}\), there are five kinds of nodes corresponding to document structure as follows:
-
Mention Node (M). Each mention node \(m\) is represented as \(n_{m} = { }\left[ {avg_{{w_{i} \in m}} \left( {h_{i}^{local} } \right);t_{m} } \right]\), where ‘;’ denotes concatenation operation, and \(t_{m}\) is an embedding to represent the node type of mention node.
-
Entity Node (E). An entity \(e\) is represented as \(n_{e} = \left[ {avg_{m \in e} \left( {n_{m} } \right);t_{e} } \right]\), where \(avg_{m \in e} \left( {n_{m} } \right)\) is the average representation of all mentions corresponding to \(e\), and \(t_{e}\) is an embedding to represent the node type of entity node.
-
Sentence Node (S). Each sentence node \(s\) is represented as \(n_{s} = { }\left[ {avg_{{w_{i} \in s}} \left( {h_{i}^{local} } \right);t_{s} } \right]\), where \(t_{s}\) is an embedding to represent the node type of sentence.
-
Chapter Node (C). A chapter node c is represented by the average representation of all sentence nodes it contains and the embedding of the node type of chapter, that is, \(n_{c} = \left[ {avg_{s \in c} \left( {h_{s}^{global} } \right);t_{c} } \right]\);
-
Document Node (D). A document node \(d\) is represented by the average representation of all chapter nodes and the embedding of the node type of document \(n_{d} = \left[ {avg_{{{\text{c}} \in d}} \left( {n_{c} } \right);t_{d} } \right]\).
Given the five kinds of nodes above, we connect them with the following six kinds of edges, as shown in Fig. 3:
-
Mention-Sentence (MS). When an entity mention \(m\) appears in a sentence, there is an edge between the corresponding entity mention node and the sentence node \(s\), and the edge is represented as \(e_{MS} = \left[ {n_{m} ;n_{s} } \right]\);
-
Mention-Mention (MM). When two entity mentions \(m_{1}\) and \(m_{2}\) appear in the same sentence \(s\), there is an edge between the two corresponding entity mention nodes \(n_{{m_{1} }}\) and \(n_{{m_{2} }}\). The edge can be represented as \(e_{MM} = \left[ {n_{{m_{1} }} ;n_{{m_{2} }} ;c_{{m_{1} m_{2} }} ;d\left( {s_{1} ,{\text{s}}_{2} } \right)} \right]\), where \(d\left( {m_{1} ,{\text{m}}_{2} } \right)\) is the representation of the relative distance between the two entity mentions in the sentence, and \(c_{{m_{1} m_{2} }}\) is the attention vector between the two entity mentions calculated by the following equations:
$$\begin{array}{*{20}c} {\alpha_{k,i} = n_{{m_{k} }}^{T} w_{i} ,} \\ \end{array}$$(1)$$\begin{array}{*{20}c} {a_{k,i} = \frac{{\exp \left( {\alpha_{k,i} } \right)}}{{\mathop \sum \nolimits_{{j \in \left[ {1,n} \right],j \notin m_{k} }} \exp \left( {\alpha_{k,j} } \right)}},} \\ \end{array}$$(2)$$\begin{array}{*{20}c} {a_{i} = \frac{{a_{1,i} + a_{2,i} }}{2},} \\ \end{array}$$(3)$$\begin{array}{*{20}c} {c_{{m_{1} ,m_{2} }} = H^{T} a,} \\ \end{array}$$(4)where \(k \in \left\{ {1,2} \right\}\), \(a_{i}\) is the attention weight of the ith word in the entity mention pair <\(m_{1} ,m_{2}\)>, and \(H \in R^{hidden\_dim \times \left| s \right|}\) is the representation of sentence \(s\);
Fig. 3 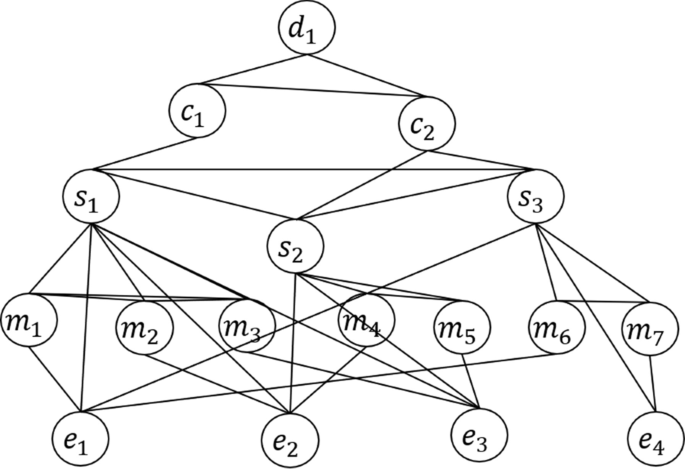
Graph to represent document structure
-
Entity-Mention (ME). There is an edge between an entity mention node \(m\) and the corresponding entity node \(e\), that is, \(e_{ME} = \left[ {n_{m} ;n_{e} } \right]\);
-
Sentence-Sentence (SS). For all sentence nodes in a document, there are edges between any two sentence nodes. An SS edge is represented by \(e_{SS} = \left[ {n_{{S_{i} }} ;n_{{s_{j} }} ;d\left( {s_{i} ,{\text{s}}_{j} } \right);\left| {n_{{S_{i} }} - n_{{s_{j} }} } \right|} \right](i \ne j)\), where \(n_{{S_{i} }}\) and \(n_{{S_{j} }}\) are the representation of \(s_{{\text{i}}}\) and the representation of \(s_{j}\), and \(d\left( {s_{i} ,{\text{s}}_{j} } \right)\) is the representation of the relative distance between \(s_{{\text{i}}}\) and \(s_{j}\) measured by the number of sentences between them;
-
Entity-Sentence (ES). When there is an entity mention node \(m\) corresponding to an entity node \(e\) in a sentence \(s\), there is an edge between \(e\) and \(s\). The edge is represented as \(e_{ES} = \left[ {n_{e} ;n_{s} } \right]\);
-
Sentence-Chapter (SC). There is an edge between a sentence node \(s\) and a chapter node \(c\), and it is represented as \(e_{SC} = \left[ {n_{s} ;n_{c} } \right]\);
-
Chapter-Chapter (CC). There is an edge between two chapter nodes \(c_{1}\) and \(c_{2}\) in a document, and it is represented as \(e_{CC} = \left[ {n_{{c_{1} }} ;n_{{c_{2} }} } \right]\);
-
Chapter-Document (CD). There is an edge between a chapter node \(c\) and a document node \(d\), and it is represented as \(e_{DC} = \left[ {n_{d} ;n_{c} } \right]\).

We further apply a linear transformation to all edge representations using the following equation:
where \(z \in \left\{ {MS,{ }MM,ME,SS,ES,SC,CC,CD} \right\}\) and \({\varvec{W}}_{z}\) is a learnable parameter matrix.
Relation extraction based on external knowledge
To utilize external knowledge, we regard any entity in external knowledge that also appears in text as an additional node and connect it to the corresponding entity node in text. In this paper, we introduce two kinds of knowledge nodes according to the forms of external knowledge of entities: (1) entity description and (2) knowledge graph.
Suppose that \(e_{1}\), \(e_{2}\) and \(e_{3}\) have their external description, \(e_{1}\) and \(e_{3}\) exist in an external knowledge graph, the graph based on document structure as shown in Fig. 3 can be extended to the graph as shown in Fig. 4 after adding knowledge nodes, where \(kd_{i}\) and \(ks_{j}\) denote knowledge node based on entity description and knowledge node based on knowledge graph, respectively. In this way, we can obtain a graph that takes full advantage of external knowledge as much as possible.

Graph based on document structure and external knowledge
Knowledge node representation based on knowledge graph
We deploy a translation distance model, a semantic matching model and a graph model, that is, TransE [12], RESCAL [13] and GAT [14], to represent knowledge nodes based on knowledge graph respectively.
TransE assumes that any triple \(\left\langle {h, r, t} \right\rangle\), where \(h\) is a head entity node, \(r\) is a relation, and \(t\) is a tail entity node, satisfies the hypothesis of \(h + r \approx t\), so as to ensure that the distance between two entity nodes is close to the representation of the relation between the two nodes. In this way, the multi-hop relation between two entities can be represented by additive transitivity, that is, if there is a relation \(r_{1}\) between \(h_{1}\) and \(t_{1}\), a relation \(r_{2}\) between \(t_{1}\) and \(t_{2}\), …, and a relation \(r_{K}\) between \(t_{K - 1}\) and \(t_{K}\), there is an implicit relation between \(h_{1}\) and \(t_{K}\) as follows:
The max-margin function of negative sampling is used as the objective function of TransE:
where \(\left( {h,r,t} \right) \in {\Delta }\) is a true triplet, while \(\left( {h^{\prime},r^{\prime},t^{\prime}} \right) \in{\Delta^{\prime}}\) is a negative triplet obtained by sampling, \(f_{r} \left( {h,t} \right)\) is the score of \(\left( {h,r,t} \right)\), and \(\gamma > 0\) denotes the margin usually set to 1. Finally, the learned \(h\) is regarded as \(h_{ks}\), the knowledge node representation corresponding to node \(ks\) without considering its type.
RESCAL captures the potential semantics between two entities through the bilinear function as follows:
As shown in Fig. 5, RESCAL represents relation triples as a three-dimensional tensor \({\mathcal{X}}\), where \({\mathcal{X}}_{ijk} = 1\) indicates that there is a true triplet \(\left\langle {e_{i} ,r_{k} ,e_{j} } \right\rangle\). The tensor decomposition model is used to model the relationship implicitly:
where \({\mathcal{X}}_{{\text{k}}}\) is the \(k\)th component of \({\mathcal{X}}\), \(A \in R^{n \times r}\) contains the potential representations of entities, \(R_{k} \in R^{r \times r}\) is a symmetric matrix used to model the potential interactions in the \(k\)th relation:
where \(h_{ks}\) is the component of \(A\) corresponding to node \(ks\).

Three-dimensional tensor used to represent relation triple in RESCAL
In addition, we also represent the knowledge node \(ks\) by the subgraph centered on the node using GAT.
Based on knowledge graph, a node \(ks\) is represented by \(n_{ks} = \left[ {h_{ks} ;t_{ks} } \right]\), where \(h_{ks}\) is the representation obtained from TransE, RESCAL or GAT, and \(t_{ks}\) is the embedding of the node type of knowledge graph node. The edge between an entity node \(e\) and the corresponding knowledge node \(k{\text{s}}\) is represented as \(e_{EKS} = \left[ {n_{e} ;n_{ks} } \right]\), and it is also further transformed into \(v_{EKS}^{\left( 1 \right)}\) via a linear transformation function:
where \({\varvec{W}}_{EKS}\) is a learnable parameter matrix.
Knowledge node representation based on description
In this paper, we use the following two methods to obtain knowledge node representation based on the entity description:
-
1.
Doc2vec [15] (also called paragraph2vec), inspired by word2vec [16] proposed by Tomas Mikolov, which can transform a sentence or a short text into a corresponding low dimensional vector representation of fixed length.
-
2.
An end-to-end neural network, as shown in Fig. 6, which are used to encode the description text of a given knowledge node, called EMB.

The end-to-end neural network used to represent the description of a given knowledge node
Similar to knowledge node \(ks\), knowledge node \(kd\) based on description is represented as \(n_{kd} = \left[ {h_{kd} ;t_{kd} } \right]\). The edge between \(kd\) and the corresponding entity node \(e\) is represented as \(e_{EKD} = \left[ {n_{e} ;n_{EKD} } \right]\) and is further transformed by
where \({\varvec{W}}_{EKD}\) is a learnable parameter matrix.
Inference
Following KEoG, with the help of the walk aggregation layer [17], a path between two entity nodes \(i\) and \(k\) of length \(2l\) can be represented as
where \(\sigma\) is the sigmoid activation function, \(\odot\) is the element-wise multiplication, and \({\varvec{W}} \in {\mathbb{R}}^{{{\varvec{d}}_{{\varvec{z}}} \times {\varvec{d}}_{{\varvec{z}}} }}\) is a learnable parameter matrix used to combine two short paths of length \(l\) (path between \(i\) and \(j\), and path between \(j\) and \(k\)) to generate one long path of length \(2l\).
All paths from node \(i\) to node \(k\) are aggregated to form the representation of the edge from node \(i\) to node \(j\) of length \(2l\) as follows:
where \(\alpha \in \left[ {0,1} \right]\) is a linear interpolation scalar to control the contribution of edges of length \(l\).
After obtaining the path representation of any entity pair of interest, we adopt the softmax function as classifier. Like in KEoG, both cross-entropy loss function and soft F-measure loss function are used as a part of the total loss function.
Experiments
Datasets
We conduct all experiments on the following two datasets:
-
Chemical-Disease Relation (CDR) dataset is a dataset for document-level chemical-induced disease (CID) relation extraction, which is provided for the BioCreative V challenge [18]. It contains a training set of 500 abstracts, a development set of 500 abstracts and a test set of 500 abstracts from PubMed.
-
Chemical Reactions dataset (CHR) dataset [9] is a dataset provided by the national text mining center (NaCTeM) of the school of computer science, University of Manchester. It contains 12,094 PubMed abstracts with their titles. Following Li et al. [11], we split the CHR dataset into a training set of 7,298 PubMed abstracts, a development set of 1,182 PubMed abstracts and a test set of 3,614 PubMed abstracts.
In this paper, MeSHFootnote 1 and Biochem4jFootnote 2 are used as the external knowledge of the CDR dataset and CHR dataset, respectively.
Experimental settings
Following our previous work, we first train all models on the training set, select the best hyper-parameters on the development set, then use the same hyper-parameters retrain on the combined set of the training set and development set, and finally report the results on the test set.
For the CDR dataset, hypernym filtering is also used to ensure that only relations between hyponym entities are kept, rather than relations between rough hypernym entities. For the CHR dataset, the entities that are not in Biochem4j are removed, and the self-relations, whose head entity and tail entity are same, are removed. The statistics of the two datasets are listed in Table 1, where “#*” denotes the number of ‘*’, the numbers split by ‘/’ are the total number of pairs and the number of inter-sentence pairs.
We start with EoG that only considers document structure, called SEoG, then investigate EoG that considers both document structure and external knowledge, i.e., SKEoG, and finally compare them with other state-of-the-art methods. For convenience, we use “SKEoG(KG + KD)”, such as “SKEoG(TransE + Doc2vec)”, to denote the SKEoG model using “KG” to obtain knowledge node representation based on knowledge graph and “KD” to obtain knowledge node representation based on entity description. All word embeddings are initialized by the pre-trained PubMed word embeddings [19]. Precision (P), recall (R) and F1-score (F1) are used as measures for model performance evaluation.
Results
We compare SEoG with other state-of-the-art methods, and the results are shown in Table 2. SEoG outperforms all other methods on the CDR and CHR test sets except KEoG(node) on the CHR dataset, which considers knowledge nodes based on the knowledge graph. To investigate the effect of the document structure presented in this paper, we further compare SEoG with its variant that does not consider chapter node, i.e., KEoG(node) without using knowledge nodes. SEoG shows much better performance than that variant (overall F1-score: 69.6 vs 67.9 on the CDR dataset, 90.4 vs 89.0 on the CHR dataset). This result indicates that the introduced chapter node is effective.
Discussion
To investigate the effect of different knowledge node representations base on the knowledge graph for SKEoG, we compare SKEoG using different knowledge node representations with SEoG and present the results in Table 3. SKEoG using a specific knowledge node representation can achieve better performance than SEoG on both the CDR and CHR datasets. On the CDR dataset, SKEoG(TransE) achieves the highest F1-score of 70.4, while SKEoG(RESCAL) achieves the highest F1-score of 91.4 on the CHR dataset. It is a little strange that SKEoG(RESCAL) and SKEoG(GAT) even perform worse than SEoG in some cases. These results may be caused by the characteristics of different knowledge graphs used for knowledge node representation. There are only three types of relations in MeSH, and each entity has only one neighbor on average, that is, most of the existing entities and relations in MeSH can be effectively modeled by TransE, rather than RESCAL and GAT. In Biochem4j, there are nine types of relations, and each entity has three neighbors on average. The one-to-many, and many-to-one complex relations in biochem4j cannot be completely modeled by TransE, but can be modeled well by RESCAL.
Moreover, we also investigate the effect of different knowledge node representations base on entity description for SKEoG by comparing SKEoG(TransE) using different knowledge node representations with SKEoG(TransE) on the CDR dataset. Table 4 shows the comparison results. We can see that the knowledge node representation learned by EMB can bring performance improvement by an F1-score of 0.3%. However, the knowledge node representation learned by Doc2vec hurts the performance of SKEoG(TransE). The results indicate that we should be careful to utilize the knowledge based on entity description.
Conclusion
We extend our previous work KEoG to SKEoG, which takes full advantage of both hierarchical document structure and external knowledge for document-level medical RE. In this study, we comprehensively investigate different methods to obtain knowledge node representation based on knowledge graph and entity description. Experimental results on two public datasets show that both document structure and external knowledge are beneficial to medical RE in the EoG framework. In the case of external knowledge, selecting proper methods for knowledge node representation is also very important.
Availability of data and materials
The datasets analyzed during the current study are available in the https://biocreative.bioinformatics.udel.edu/tasks/biocreative-v/track-3-cdr/ (accessed: Sep. 17, 2021) website and in the http://www.nactem.ac.uk/CHR/ (Sep. 17, 2021) website.
Abbreviations
- RE:
-
Relation extraction
- CDR:
-
Chemical-disease relation
- CHR:
-
Chemical reactions dataset
- NLP:
-
Natural language processing
- MIL:
-
Multi-instance learning
- GNNs:
-
Graph neural networks
- EoG:
-
Edge-oriented GNNs
References
Socher R, Huval B, Manning CD, Ng AY. Semantic compositionality through recursive matrix-vector spaces. In: Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, Jeju Island, Korea, July 2012. p. 1201–11. Accessed 16 Oct 2020 [Online].
Zeng D, Liu K, Lai S, Zhou G, Zhao J. Relation classification via convolutional deep neural network. In: Proceedings of COLING 2014, the 25th international conference on computational linguistics: technical papers, Dublin, Ireland, Aug 2014. p. 2335–44. Accessed 16 Oct 2020 [Online].
Gu J, Sun F, Qian L, Zhou G. Chemical-induced disease relation extraction via convolutional neural network. Database. 2017. https://doi.org/10.1093/database/bax024.
Verga P, Strubell E, McCallum A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, New Orleans, Louisiana, Jun 2018, vol. 1. p. 872–84. Accessed 26 Oct 2020 [Online].
Nguyen DQ, Verspoor K. Convolutional neural networks for chemical-disease relation extraction are improved with character-based word embeddings. In: Proceedings of the BioNLP 2018 workshop, Melbourne, Australia, 2018. p. 129–36.
Zeng D, Liu K, Chen Y, Zhao J. Distant supervision for relation extraction via piecewise convolutional neural networks. In: Proceedings of the 2015 conference on empirical methods in natural language processing, Lisbon, Portugal, Sept 2015. p. 1753–62. Accessed 16 Oct 2020 [Online].
Jiang X, Wang Q, Li P, Wang B. Relation extraction with multi-instance multi-label convolutional neural networks. In: Proceedings of the 26th international conference on computational linguistics: technical papers, Osaka, Japan, Dec 2016. p. 1471–80. Accessed 16 Oct 2020 [Online].
Kipf T, Welling M. Semi-supervised classification with graph convolutional networks. Presented at the international conference on learning representations, 2017.
Sahu SK, Christopoulou F, Miwa M, Ananiadou S. Inter-sentence relation extraction with document-level graph convolutional neural network. In: Proceedings of the 57th annual meeting of the association for computational linguistics, Florence, Italy, 2019. p. 4309–16.
Christopoulou F, Miwa M, Ananiadou S. Connecting the dots: document-level neural relation extraction with edge-oriented graphs. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing, 2019. p. 4927–38.
Li T, Peng W, Chen Q, et al. KEoG: a knowledge-aware edge-oriented graph neural network for document-level relation extraction. In: 2020 IEEE international conference on bioinformatics and biomedicine (BIBM). IEEE, 2020. p. 1740–7.
Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data. In: Neural information processing systems (NIPS); 2013. p. 1–9.
Nickel M, Tresp V, Kriegel H-P. A three-way model for collective learning on multi-relational data. In: International conference on machine learning, 2011, vol. 11. p. 809–16.
Velickovic P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y. Graph attention networks. Presented at the international conference on learning representations, 2018.
Le Q, Mikolov T. Distributed representations of sentences and documents. In: Proceedings of the 31st international conference on machine learning, Beijing, China, 2014, vol. 32. p. II-1188–96.
Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space, 2013.
Christopoulou F, Miwa M, Ananiadou S. A walk-based model on entity graphs for relation extraction. In: Proceedings of the 56th annual meeting of the association for computational linguistics, Melbourne, Australia, 2018. p. 81–8. Accessed 16 Oct 2020.
Li J, et al. BioCreative V CDR task corpus: a resource for chemical disease relation extraction. Database. 2016;2016:2016.
Chiu B, Crichton G, Korhonen A, Pyysalo S. How to train good word embeddings for biomedical NLP. In: Proceedings of the 15th workshop on biomedical natural language processing, Berlin, Germany, 2016. p. 166–74. https://doi.org/10.18653/v1/W16-2922.
Verga P, Strubell E, McCallum A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, vol. 1 (long papers), New Orleans, Louisiana, 2018. p. 872–84. https://doi.org/10.18653/v1/N18-1080.
Acknowledgements
Not applicable.
About this supplement
This article has been published as part of BMC Medical Informatics and Decision Making Volume 21 Supplement 7 2021:Selected articles from the Fifth International Workshop on Semantics-Powered Data Mining and Analytics (SEPDA 2020). The full contents of the supplement are available at https://bmcmedinformdecismak.biomedcentral.com/articles/supplements/volume-21-supplement-7.
Funding
Publication costs are funded by NSFCs (National Natural Science Foundations of China) (U1813215 and 61876052), National Key Research and Development Program of China (2017YFB0802204), Special Foundation for Technology Research Program of Guangdong Province (2015B010131010), Natural Science Foundation of Guangdong Province (2019A1515011158), Strategic Emerging Industry Development Special Funds of Shenzhen (JCYJ20180306172232154) and Innovation Fund of Harbin Institute of Technology (HIT.NSRIF.2017052). All the funders do not play any role in the design of the study, the collection, analysis, and interpretation of data, or in writing of the manuscript.
Author information
Authors and Affiliations
Contributions
TL, YX and BT design the experiments, TL and BT write the manuscript, and TL, YX, XW, QC and BT revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent to publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Li, T., Xiong, Y., Wang, X. et al. Document-level medical relation extraction via edge-oriented graph neural network based on document structure and external knowledge. BMC Med Inform Decis Mak 21 (Suppl 7), 368 (2021). https://doi.org/10.1186/s12911-021-01733-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-021-01733-1